intepret chi-square fit test in lavaan package|lavaan in r : fabrication The lavInspect () and lavTech () functions can be used to inspect/extract information that is stored inside (or can be computed from) a fitted lavaan object. Note: the (older) inspect () .
Resultados del Super 11. miércoles, 28 de febrero de 2024. Sorteo anterior. Combinación ganadora del Sorteo 3 del Super 11. 03. 04. 07. 10. 16. 21. 25. 26. 29. 32. 44. 50. 52. 54. .
{plog:ftitle_list}
20 de dez. de 2023 · Living the Survivor Dream. S45 E13 129min TV-PG. The remaining five castaways must stack up a win in the immunity challenge to secure a spot in the final four. Then, one castaway will be crowned .
2) The chi-square statistic (labeled as the minimum function test statistic) is used to perform a test of perfect model fit, both for your specified and null/baseline models. It .6. I am trying to replicate a path analysis SEM model using Lavaan in R, and was .6. I am trying to replicate a path analysis SEM model using Lavaan in R, and was very confused about the results that it gave regarding the model fit statistics. The code is as follows: #Import .
Lavaan Lab 9: Model Fit Part I (Test Statistics) In this lab, we will learn: how to calculate and interpret chi-square statistics for SEM models. how to compare nested models using chi-square difference test. Load up the lavaan and .
lavaan testing examples
The lavaan tutorial explains well how to formalize a theoretical model. It even includes a measurement invariance testing example. In a nutshell: Factor loadings in R are indicated by .The lavInspect () and lavTech () functions can be used to inspect/extract information that is stored inside (or can be computed from) a fitted lavaan object. Note: the (older) inspect () . The resulting estimates are controversial. Indeed, all the measures to check the fit are quite good: CFI= 0.978; TLI=0.96; RMSEA=0.028; SRMR=0.020; but the p-value of the . Lavaan allows users to test the fit of their model using several fit indices, such as chi-square, RMSEA, CFI, and TLI.
I want to understand the output of the fitmeasures() from the lavaan class in RStudio. I'm learning R on my own and would love some help on deciphering what these .In this example, we use three different formula types: latent variable definitions (using the =~ operator), regression formulas (using the ~ operator), and (co)variance formulas (using the ~~ .By default, lavaan outputs the model chi-square a.k.a Model Test User Model. To request additional fit statistics you add the fit.measures=TRUE option to summary, passing in the lavaan object onefac8items_a.
In fact, the two functions are currently almost identical, but this may change in the future. In the summary() function, we omitted the fit.measures = TRUE argument. Therefore, you only get the basic chi-square test statistic. The argument standardized = TRUE augments the output with standardized parameter values. Two extra columns of . I am doing a path analysis in R using the lavaan package. Because one of my endogenous variables is skewed I used a correction by Satorra & Bentler to receive robust estimators and standard errors. fit<-sem(trf.model1, data=data2, estimator="MLM") summary(fit, standardized=T, fit.measures=T, rsquare=T) A Chi-square (p-value) of a single group SEM is easy to interpret. It is a measure of exact fit. When one runs a multiple group, say grouping the data by gender or by the presence of a condition like a disease, lavaan outputs a chi-square, together with the chi-square of the particular groups.
In addition, the chi-square statistic is computed by multiplying the minimum function value with a factor N (instead of N-1). If you prefer to use an unbiased covariance matrix, and \(N-1\) as the multiplier to compute the chi-square statistic, you need to specify the likelihood = "wishart" argument when calling the fitting functions. For example: Figure 5. Correlation matrix plot of the items with hierarchical clustering. Next, using the lavaan package (see https://lavaan.ugent.be/ for more information on the package), we will estimate a series of multi-group CFA models using gender as a group variable. For all of the models, the baseline model is the same: a two-factor model where the positively-worded .
Getting Started with Structural Equation Modeling Part 1Getting Started with Structural Equation Modeling: Part 1 Introduction For the analyst familiar with linear regression fitting structural equation models can at first feel strange. In the R environment, fitting structural equation models involves learning new modeling syntax, new plotting syntax, and often a new .Details. The anova function for lavaan objects simply calls the lavTestLRT function, which has a few additional arguments.. The only test= options that currently have actual consequences are "satorra.bentler", "yuan.bentler", or "yuan.bentler.mplus" because "mean.var.adjusted" and "scaled.shifted" are currently distinguished by the scaled.shifted argument. . See lavOptions .1 Course; 2 Into to R. 2.1 R as a calculator; 2.2 Assigning Objects and Basic Data Entry; 2.3 Removing an object from the workspace; 2.4 Formal Rules for Indexing Objects in R; 2.5 Examples; 3 Lavaan Lab 1: Path Analysis Model. 3.1 Reading-In and Working With Realistic Datasets In R; 3.2 Sample Covariance Matrices using the cov() function; 3.3 Installing .
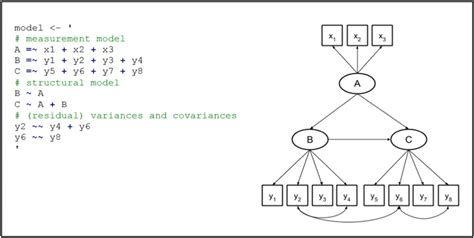
3.1 Implement the CFA, First Model. Using the lavaan package, we can implemnt directly the CFA with only a few steps. Since this document contains three different packages’ approach to CFA, the packages used for each will be loaded at that point, so as to not have confusion over common function names.Package example. The package is very straightforward to use, simply call the lavaanPlot function with your lavaan model, adding whatever graph, node and edge attributes you want as a named list (graph attributes are specified as a standard default value that shows you what the other attribute lists should look like). For your reference, the available attributes can be found here:
The image above indicates the SEM model is a good fit, the chi-square test shows that it’s not significant, though one can’t rely on this due to its sensitivity to large samples, and the CFI .11.2 Plotting SEM models with the semPlot package. The semPlot package (Epskamp 2022) package provides a convenient way to plot SEM models fitted by lavaan.In principle, all that is needed to plot a lavaan-estimated object mod is a call to semPlot::semPaths(mod).However, the default settings don’t necessarily provide the best looking plots. But the semPlot package is .
3. Chi-square test of goodness of fit. The Chi-square test of goodness of fit is used to compare observed frequencies with expected frequencies in a single categorical variable. It helps determine whether the observed data follows a specific theoretical distribution or if there is a significant deviation.
Step 1: System of paths and directed acyclic graphs (DAGs) Everything starts with path analysis. Richard Sewall Wright (1921), a hundred years ago described a system of finding correlation between two variables, X and Y using a system of paths (Denis 2021).In this approach, he described that if a system of paths exist between two variables X and Y, the multiplication .lavobject: An object of class lavaan.. test: Character vector. Multiple names of test statistics can be provided. If "standard" is included, a conventional chi-square test is computed. If "Browne.residual.adf" is included, Browne's residual-based test statistic using ADF theory is computed. If "Browne.residual.nt" is included, Browne's residual-based test statistic using . The lavaan package is currently still a beta-version package and not considered complete. That said, it is approaching the functionality of some commercial packages. One feature of lavaan is that it does not require you to be an expert in R. You do need to know how to import datasets into R and how to execute commands. You also need to know how to%PDF-1.4 %ÐÔÅØ 3 0 obj /pgfprgb [/Pattern /DeviceRGB] >> endobj 6 0 obj /Length 539 /Filter /FlateDecode >> stream xÚ•“Ms›0 †ïüŠ= EŸHôÖ6mfr«K O [8žbH§“ ßE ö؇^ÐJÚ/½û@a ’/Ur÷]H ¤4L@U 3„I \ Dq Õ Öé½{±}–KšŽ ׎YεI»:¬÷v´ÁúÜÚæ}Ø ÙSõ Ü”Ä( U|Š‡çSà¯vÿ–q•º~Ø ï“sòJ^ †¾ ØG ’(SÀæ ¬Ÿ(lñî (áFÀ_ïyÁ±IY .
Where: Χ 2 is the chi-square test statistic; Σ is the summation operator (it means “take the sum of”) O is the observed frequency; E is the expected frequency; The larger the difference between the observations and the expectations (O − E in the equation), the bigger the chi-square will be.To decide whether the difference is big enough to be statistically significant, . Here we’re interested in the Chi-square difference test, which formally compares the second (metric invariance) to the first (configural invariance) model. Here we test whether the difference in model fit between the two models is significant. In other words, we test whether the constraints imposed made the model fit significantly worse.Consider a classical mediation setup with three variables: Y is the dependent variable, X is the predictor, and M is a mediator. For illustration, we create a toy dataset containing these three variables, and fit a path analysis model that includes the direct effect of X on Y and the indirect effect of X on Y via M.
lavaan output interpretation
4 Moderated mediation analyses using “mediation” package. We will first create two regression models, one looking at the effect of our IVs (time spent in grad school, time spent with Alex, and their interaction) on our mediator (number of publications), and one looking at the effect of our IVs and mediator on our DV (number of job offers).If not NULL, an object of class lavaan, representing a user-specified alternative to the default unrestricted model. If h1.model is provided, all fit indices calculated from chi-squared will use the chi-squared difference test statistics from lavTestLRT, which compare the user-provided h1.model to object. fm.args: List. Note that it is very common to have a non-significant Chi-squared fit statistic in CFA testing, as it is heavily sensitive to large sample sizes and higher model complexity (i.e. a number of indicators in your model). In your case, it is very unsurprising that the Chi-squared in non-significant, but both CFI and TLI are large.The message shown in the output just underlines that the reported chi-square statistics are standard ones since the robust difference test is a function of two standard Chi-square statistics. It is worth noting that the Chi-square test is sensitive to sample size. In large samples, even trivial differences in fit between two models can result .
1 Course; 2 Into to R. 2.1 R as a calculator; 2.2 Assigning Objects and Basic Data Entry; 2.3 Removing an object from the workspace; 2.4 Formal Rules for Indexing Objects in R; 2.5 Examples; 3 Lavaan Lab 1: Path Analysis Model. 3.1 Reading-In and Working With Realistic Datasets In R; 3.2 Sample Covariance Matrices using the cov() function; 3.3 Installing .11.3 Other descriptive fit indices. Below, we give a short description of other popular descriptive fit indices. We limit our discussion to the fit indices that are provided by lavaan’s summary() output (which are also the indices provided by Mplus), although many additional indices are available from lavaan’s fitMeasures() function, as well as the moreFitIndices() function in the .
For those who want to just dive in the lavaan package seems to offer the most comprehensive feature set for most SEM users and has a . # Specify the model mod1 <- "ILL ~ IMM \n IMM ~ DEP" # Give lavaan the command to fit the model mod1fit <- sem(mod1, sample.cov = mat1, sample.nobs = 500) # Specify model 2 mod2 <- "DEP ~ ILL\n ILL ~ IMM .
best sampling method for quantitative research
lavaan in r testing
hottestdeborah. FOLLOW. 0 ALBUM 0 VIEW 15 FOLLOWERS. hottestdeborah's profile page. EroMe is the best place to share your erotic pics and porn videos. Every day, .
intepret chi-square fit test in lavaan package|lavaan in r